
이번 편이 만지는 곳: 개발의 AI 모델과 데이터. 키워드와 벡터, 하이브리드 세 검색을 서브에이전트로 만들어 비교한다.
데이터가 쌓였으니 이제 찾는 문제다. 검색은 "그냥 만들어 줘" 하면 AI가 한 방식만 골라 붙이고 끝나기 쉬운데, 거기서 서비스 품질이 갈린다. 이번 편에서는 키워드와 벡터, 하이브리드 세 가지 검색을 직접 만들어 같은 질문을 던져 보고, 결과 차이를 눈으로 비교한다. 그리고 그 셋을 서브에이전트로 한 번에 만든다.
새로 쓰는 Claude Code 기능은 두 가지다. 작업을 나눠 맡기는 서브에이전트, 그리고 최신 라이브러리 문서를 끌어와 환각을 줄이는 Context7 플러그인. 이전 편에서 익힌 Plan Mode와 CLAUDE.md, /rewind는 계속 쓴다.
세 가지 검색 — 도서관에서 책 찾기

- 키워드 검색은 제목에 그 단어가 정확히 든 책을 찾는다. 빠르고 정확하지만 동의어나 오타에 약하다. (대표 순위 알고리즘이 BM25로, 단어 빈도를 기반으로 점수를 매긴다.)
- 벡터(의미) 검색은 "이런 주제의 책"을 찾는다. 글의 뜻을 숫자 좌표(임베딩)로 바꿔 뜻이 가까운 것끼리 찾으니 동의어엔 강하지만, 정확한 품번이나 고유명사는 놓친다.
- 하이브리드 검색은 둘을 합쳐 점수를 섞는다. 찾은 문서로 답을 만드는 RAG(Retrieval-Augmented Generation: 검색 증강 생성)의 품질을 끌어올린다.
도서관에서 "머신러닝" 책을 찾는다고 해 보자. 키워드 검색은 제목에 정확히 "머신러닝"이 든 책만 준다. "AI 입문"은 같은 주제인데도 놓친다. 벡터 검색은 뜻이 비슷한 책을 주니 "AI 입문"도 찾지만, 정확한 책 번호 "ML-203"을 대면 오히려 헷갈려 한다. 그래서 둘 다 쓰는 하이브리드가 답이다. 우리 서비스에 어느 쪽이 더 중요한지는 우리가 정해 줘야 한다.
서브에이전트 — 보조 일꾼 여러 명
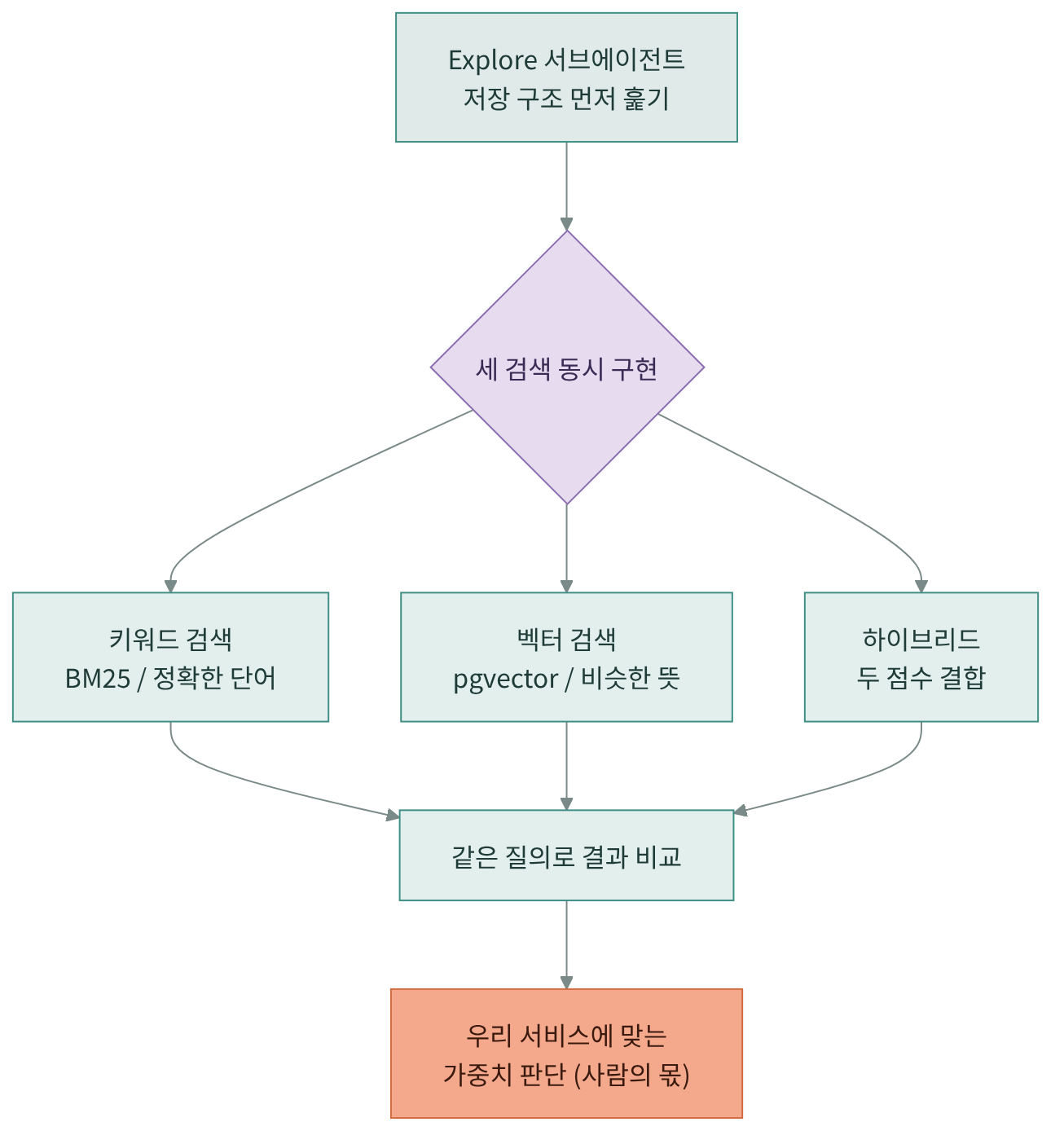
Claude Code는 작업을 여러 보조 에이전트에게 나눠 시킬 수 있다. 기본으로 Explore(코드를 읽기만 하며 훑는 탐색 전용)와 Plan(계획)이 제공되고, .claude/agents/에 직접 만들 수도 있다. 오늘은 이걸로 세 검색을 동시에 만든다. 검색 셋을 하나씩 차례로 만드는 것보다, 서브에이전트로 동시에 만들면 비교가 빨라지고 긴 탐색이 본체 대화를 어지럽히지 않는다. 작업을 /todos로 쪼개 추적하면 빠진 단계도 줄어든다. 전체 흐름은 이렇다.
🗂️ 실습 데이터 — 만들기와 쓰기
세 검색을 나란히 비교하려면 같은 코퍼스부터 깔려 있어야 한다. 코퍼스가 비면 셋 다 0건이라 비교할 게 없다. 넣는 방법은 둘이다.
① 직접 생성 (검색 차이가 드러나게 설계해서)
'문서 질의응답/스터디 관리' 데모용 한국어 문서 30개를 만들어 data/docs/ 에 .md로 저장해 줘.
검색 비교가 드러나게 (1) 같은 주제를 '정식 용어' 문서와 '동의어/약칭' 문서로 나눠 쓰고
(2) 정확한 코드(STUDY-203 같은)를 일부 문서에 넣고 (3) 오타 유발 용어를 섞어 줘.
각 문서는 제목과 6~10문장.② 내려받아 쓰기 — 위 설계대로 만든 30개를 묶어 뒀다 (studyqa-docs-core.zip 내려받기).
임베딩은 내 노트북에 맞춰 (임베딩엔 GPU가 필요 없다. CPU로 충분)
내 노트북은 [RAM 8GB / CPU 4코어 / GPU 없음]이야. 이 문서들을 임베딩하려는데
로컬에서 무리 없이 돌릴 모델과 방식(Ollama / fastembed / 사전계산)을 트레이드오프와 함께
추천하고, 고른 모델 차원에 맞춰 적재 설정을 잡아 줘.적재(임포트)
내려받은 zip을 data/docs/ 에 풀고, 문서를 잘게 쪼개(청크) 임베딩한 뒤 pgvector에 넣는
스크립트로 적재해 줘. 각 행에 임베딩 모델 버전(embedding_model_version)을 같이 저장해.코퍼스가 들어왔으면 아래 세 질의로 차이를 본다. 컨테이너 오케스트레이션(키워드는 0건인데 벡터는 쿠버네티스/k8s 문서를 찾음), 임배딩(오타), STUDY-203(코드는 키워드가 정확).
따라하기 1 — 최신 API부터 확인 (Context7)
/plugin install context7@claude-plugins-official
pgvector로 벡터 검색을 붙이려고 해. Context7로 최신 사용법을 확인해서
환각 없이 정확한 코드로 알려 줘.여기서 pgvector는 벡터를 저장하고 검색하게 해 주는 PostgreSQL 확장이다. 임베딩을 만들고 벡터로 검색하는 이런 AI 작업은 이 편부터 FastAPI(Python) 백엔드가 맡는다. 임베딩과 모델 호출은 Python 생태계가 강해서다. AI가 기억이 아니라 최신 문서에 근거하는지 본다. 버전이 자주 바뀌는 라이브러리일수록 이 한 단계가 중요하다.
따라하기 2 — 서브에이전트로 세 검색 동시 구현
Explore 서브에이전트로 우리 문서 저장 구조를 먼저 훑은 뒤,
같은 문서 데이터에 (1) 키워드 검색 (2) 벡터 검색(pgvector) (3) 하이브리드 검색을
각각 붙여 줘.세 검색이 각각 동작하는지 확인한다. Explore가 저장 구조를 먼저 읽어 두면, 셋이 같은 데이터를 같은 눈으로 바라본다.
따라하기 3 — 같은 질의, 세 결과 비교
같은 질의를 세 검색에 동시에 던져 결과를 나란히 보여 주는 화면을 만들어 줘.이제 세 종류의 질의를 차례로 던진다. 오타가 섞인 질의, 동의어 질의, 정확한 고유명사 질의. 키워드 검색이 오타와 동의어에 약하고 벡터가 거기서 강한 차이가 눈에 보이는가? 정확한 고유명사에서는 반대 양상이 보이는가? 하이브리드가 두 경우 모두 무난한가?
따라하기 4 — 함정과 가중치 조정 (오늘의 시연)
일부러 모호하게 지시해 본다.
검색 기능 만들어 줘.AI는 키워드만, 또는 벡터만 골라 한쪽 약점을 그대로 노출한다. 그때 묻는다. "오타와 동의어는? 정확한 품번은? 우리 서비스엔 어느 비중이 맞나?" 비중은 우리가 직접 정해 준다.
키워드와 벡터 가중치를 7:3으로 조정하고, 이유를 주석으로 달아 줘.띄워서 확인 — 에이전트가 한 일을 검증한다
검색이 결과를 뱉는다고 좋은 검색은 아니다. 에이전트는 "검색"이라고만 하면 키워드 한 종류로 끝내 버리곤 한다. 그래서 시킨 결과를 그대로 믿지 말고 무엇을 만들었는지 직접 본다. 세 검색이 정말 따로 동작하는지 결과를 나란히 띄워 보고, "왜 이 방식만 골랐는지" 되묻고, 오타와 고유명사가 섞인 질의를 일부러 던져 약점을 드러낸다.
세 검색 비교 화면을 띄우고, 방금 본 질의들을 다시 넣어 결과 차이를 확인해 줘.- 오타와 동의어 질의에서 키워드는 약하고 벡터가 강한 차이가 보이는가?
- 정확한 고유명사에서 반대 양상이 보이는가?
- 하이브리드가 두 경우 모두 무난한가?
한 겹 더 — 점수와 빈 상태
검색 결과에 점수(score)를 함께 표시하고, 결과가 0건일 때 빈 상태 화면도 만들어 줘.점수가 보이는지, 0건일 때 빈 화면이 제대로 뜨는지 확인한다.
벡터가 바뀔 때 — 재임베딩과 차원 변경
벡터 검색에는 일반 테이블에 없는 함정이 하나 있다. 저장된 벡터는 "그때 그 임베딩 모델"이 만든 좌표라, 모델을 바꾸거나 벡터 차원이 달라지면 옛 벡터와 새 벡터를 같은 자로 잴 수 없다. 그래서 두 종류의 변경을 갈라서 다룬다.
- 스키마 변경(차원) — 임베딩 모델을 바꿔 차원이 1536에서 1024로 달라지면, 벡터 컬럼 정의를 바꾸는 마이그레이션과 함께 전체 문서를 다시 임베딩해야 한다. 절반만 새 모델로 채우면 검색이 뒤섞인다.
- 데이터 변경(내용) — 원본 문서가 수정되거나 지워지면 그 문서의 벡터도 같이 새로 만들거나 지운다. 본문은 바뀌었는데 옛 벡터가 남으면, 검색은 사라진 내용을 계속 가리킨다.
임베딩 모델이나 벡터 차원이 바뀌는 경우와 원본 문서가 갱신되는 경우를 나눠,
재임베딩 배치와 벡터 갱신/삭제를 안전하게 돌리는 마이그레이션 절차를 만들어 줘.
(각 행에 임베딩 모델 버전을 같이 저장해, 옛 모델로 만든 벡터를 골라낼 수 있게.)모델 버전을 함께 저장해 두면 옛 모델로 만든 벡터만 골라 다시 임베딩할 수 있다. 차원이 바뀌는 변경은 02편의 마이그레이션 규율(검토 가능한 SQL, 적용 전 스냅샷)을 그대로 따른다. 벡터 테이블도 결국 같은 데이터베이스 안의 테이블이라, 되돌리기 안전망이 똑같이 필요하다.
이제 찾는 문제는 풀었다. 다음 편에서는 찾은 문서로 답을 만든다. 캐시로 속도를 올리고, MCP로 데이터베이스를 도구처럼 연결해 스스로 도구를 쓰는 에이전트를 붙인다.