
오늘 아침을 한 번 되감아 보자. 알람이 추천한 기상 시간, 지도 앱이 찍어 준 도착 예정 시각, 유튜브와 쇼핑이 들이민 추천, 메일함이 알아서 걸러 낸 스팸, 사진첩이 같은 얼굴끼리 묶어 둔 앨범. 여기까지 벌써 다섯 번, 우리는 이미 AI(Artificial Intelligence: 인공지능)를 썼다. AI는 멀리 있는 대단한 무엇이 아니라 이미 손안에서 조용히 돌아가고 있다.
이 글은 그 AI가 마법이 아니라 어떻게 작동하는지를 가장 단순한 직관으로 잡고, 한 걸음 더 들어가 AI/머신러닝/딥러닝이 각각 어떻게 다르게 동작하는지, 그 안에 어떤 알고리즘과 모델이 있는지까지 본다. 이틀짜리 입문 과정의 지도이고, 코드는 한 줄도 쓰지 않는다.
모델은 결국 "함수"다 — 넣으면 나오는 상자
AI를 이해하는 가장 쉬운 한 문장은 이거다. 모델은 무언가를 넣으면 답을 내놓는 상자다. 입력을 받아 처리하고 출력을 내보낸다. 자판기를 떠올리면 된다. 동전을 넣고(입력) 버튼을 누르면 음료가 나온다(출력). 안에서 무슨 일이 벌어지는지 몰라도 "넣으면 나온다"는 건 안다. 앞으로 보게 될 모든 AI(사진을 알아보는 것, 그림을 그리는 것, 글을 쓰는 것)를 전부 이 "넣으면 나오는 상자"로 보면 된다.
같은 상자인데, 속을 채우는 방식이 다르다
상자 안의 규칙은 누가 채울까. 여기서 AI의 갈래가 갈린다. 세 방식을 나란히 두면 차이가 한눈에 보인다.
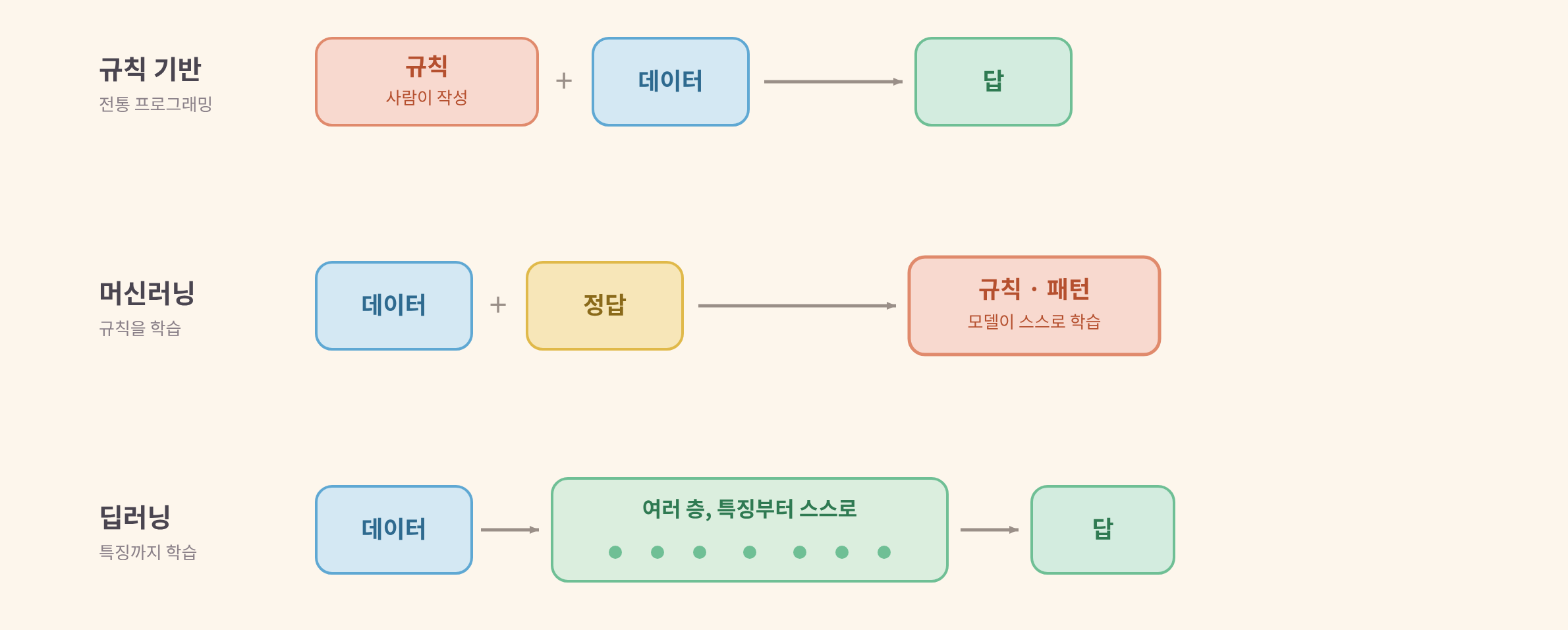
규칙 기반은 사람이 규칙을 직접 적는다. "제목에 '당첨'이 있으면 스팸" 같은 조건을 손으로 나열한다. 규칙과 데이터를 넣으면 답이 나온다. 명확하지만, 예외가 늘 때마다 규칙도 끝없이 길어진다. 초기 체스 프로그램이나 규칙형 스팸 필터가 이 방식이다.
머신러닝은 그림을 뒤집는다. 규칙을 넣는 게 아니라, 데이터와 정답을 넣으면 규칙을 모델이 스스로 찾아낸다. 스팸 1만 통과 정상 1만 통을 보여 주면 "이런 특징이 있으면 스팸이더라"를 직접 학습한다. 다만 무엇을 볼지(단어 빈도, 발신자 같은 특징)는 사람이 골라 준다.
딥러닝은 한 걸음 더 간다. 무엇을 볼지(특징)마저 데이터에서 스스로 찾는다. 사람이 "이 점을 봐라"라고 안 알려줘도, 여러 층을 거치며 낮은 특징(선, 점)에서 높은 특징(눈, 얼굴)까지 알아서 쌓아 올린다. 층이 깊어서 '딥'이다.
핵심은 위 그림에서 "규칙"이 놓이는 자리다. 규칙 기반에서는 규칙이 왼쪽(사람이 넣는 입력)에 있지만, 머신러닝에서는 규칙이 오른쪽(모델이 내놓는 결과)으로 옮겨 간다. 이 한 번의 뒤집기가 오늘날 AI의 출발점이다.
그래서 각 갈래엔 어떤 알고리즘과 모델이 있나
이름을 다 외울 필요는 없다. "이런 게 이 갈래에 속하는구나" 정도만 잡으면 된다. 아래 표의 상당수를 이틀 동안 직접 만져 본다.
| 갈래 | 어떻게 동작하나 | 대표 알고리즘 / 모델 |
|---|---|---|
| 규칙 기반 AI | 사람이 규칙을 직접 작성 | 전문가 시스템, 규칙 엔진, 탐색/계획 알고리즘 |
| 머신러닝 (특징은 사람이 고름) | 데이터+정답으로 패턴을 학습 | 선형 회귀(예측), 로지스틱 회귀/결정 트리/랜덤 포레스트/SVM/kNN(분류), k-평균(군집) |
| 딥러닝 (특징까지 스스로) | 신경망이 여러 층으로 특징부터 학습 | CNN(이미지), RNN/Transformer(언어/순서), GAN/Diffusion(생성), LLM(대화/글) |
표의 약자들은 지금 외우지 않아도 된다. 다음 글들에서 하나씩 직접 만지며 풀어 본다. 우선 다음 글에서 전통 머신러닝(회귀로 예측, k-평균으로 군집, 분류)을 손으로 가르쳐 보고, 이어서 딥러닝 쪽으로 넘어가 이미지를 알아보는 Vision(CNN(Convolutional Neural Network: 합성곱 신경망)), 이미지를 만드는 생성 모델, 그리고 둘째 날의 LLM(Large Language Model: 대규모 언어 모델)까지 차례로 본다.
큰 그림으로 — AI 안의 ML, ML 안의 DL
그래서 세 단어는 경쟁 관계가 아니라 포함 관계다. 동심원으로 보면 한 번에 정리된다.
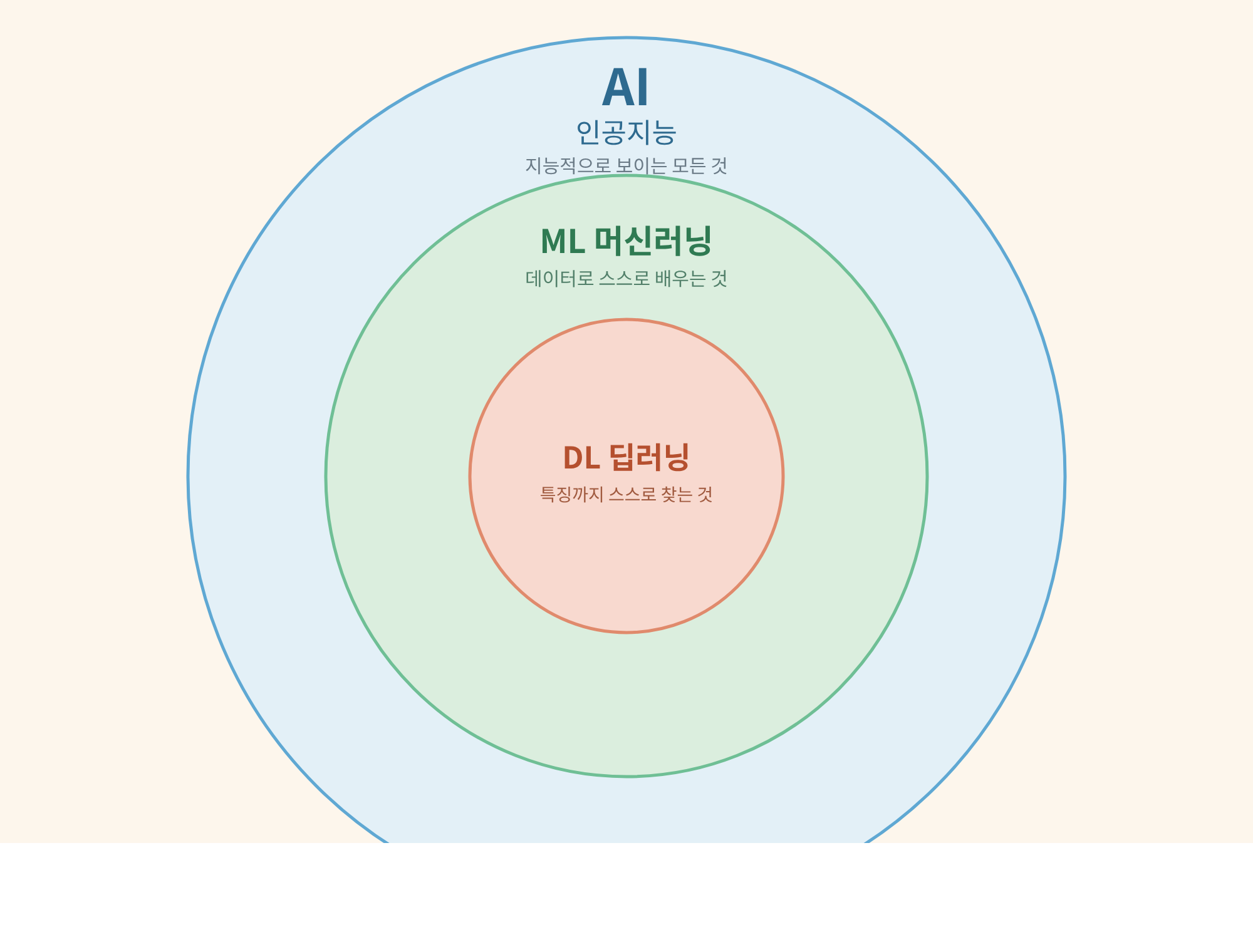
- AI(인공지능) — 가장 큰 원. 지능적으로 보이는 모든 것(규칙 기반까지 포함).
- ML(Machine Learning: 머신러닝) — 그 안의 원. 데이터로 스스로 배우는 것.
- DL(Deep Learning: 딥러닝) — 가장 안쪽 원. 신경망이 특징까지 스스로 찾는 것.
요즘 화제의 생성 AI나 ChatGPT 같은 것들은 거의 다 가장 안쪽 원(딥러닝)에서 나온다. 하지만 그게 AI의 전부는 아니다. 바깥 두 원도 지금 우리 일상에서 멀쩡히 돌아가고 있다.
해 보기 — 내가 오늘 쓴 AI를 함수로 적어 보기
개념을 길게 외우는 것보다 한 번 적어 보는 게 빠르다. 오늘 쓴 AI 세 개를 떠올려, 각각을 "무엇을 넣으면(입력) 무엇이 나오나(출력)"로 한 줄씩 적어 보자.
지도 앱: 출발지와 목적지(입력) → 도착 예정 시각(출력)
사진첩: 사진 수천 장(입력) → 같은 얼굴끼리 묶은 앨범(출력)
유튜브: 내가 본 영상들(입력) → 다음에 볼 만한 추천(출력)여유가 되면 각각이 어느 갈래일지도 가늠해 보자. 사진첩의 얼굴 묶기는 딥러닝, 도착 시각 예측은 머신러닝 쪽에 가깝다. 정답을 맞히는 게 목적이 아니라 "전부 넣으면 나오는 함수"라는 눈을 들이는 게 목적이다.
이틀 지도 — 앞으로 무엇을 보나
오늘(1일차)은 전통 머신러닝(예측/군집/분류)에서 보는 AI(Vision)와 만드는 AI(이미지/음성/음악 생성)로 간다. 내일(2일차)은 요즘 가장 뜨거운 LLM이 어떻게 작동하는지(컨텍스트)부터, 글/표/검색/문서/RAG(Retrieval-Augmented Generation: 검색 증강 생성)로 활용하는 법, 그리고 나만의 AI를 만드는 데까지 간다.
모든 실습은 클릭과 대화로만 한다. 코드는 쓰지 않는다. 오늘 잡은 직관 하나, AI는 데이터로 패턴을 찾는 함수이고, 깊어질수록 특징까지 스스로 찾는다만 들고 가면 나머지는 만지면서 자연스럽게 따라온다. 다음 글에서는 그 첫 갈래, 전통 머신러닝의 회귀/군집/분류를 손으로 직접 가르쳐 본다.