
LLM(Large Language Model: 대규모 언어 모델)은 아는 게 많지만, 내 회사 규정이나 우리 팀 노트는 모른다. 모르면 어떻게 할까. 그럴듯하게 지어낸다. 이게 환각이다. 그렇다고 AI에게 사실을 강요할 수는 없다. 대신 근거를 쥐여 줄 수는 있다.
시험 직전에 컨닝페이퍼를 손에 쥐여 주는 장면을 떠올려 보자. 답을 외우게 하는 게 아니라, 답하기 전에 내가 준 자료를 먼저 찾아보게 하는 것이다. 이 방식이 RAG(Retrieval-Augmented Generation: 검색증강생성)다.
RAG = 찾고(검색) 그 근거로 답한다(생성)
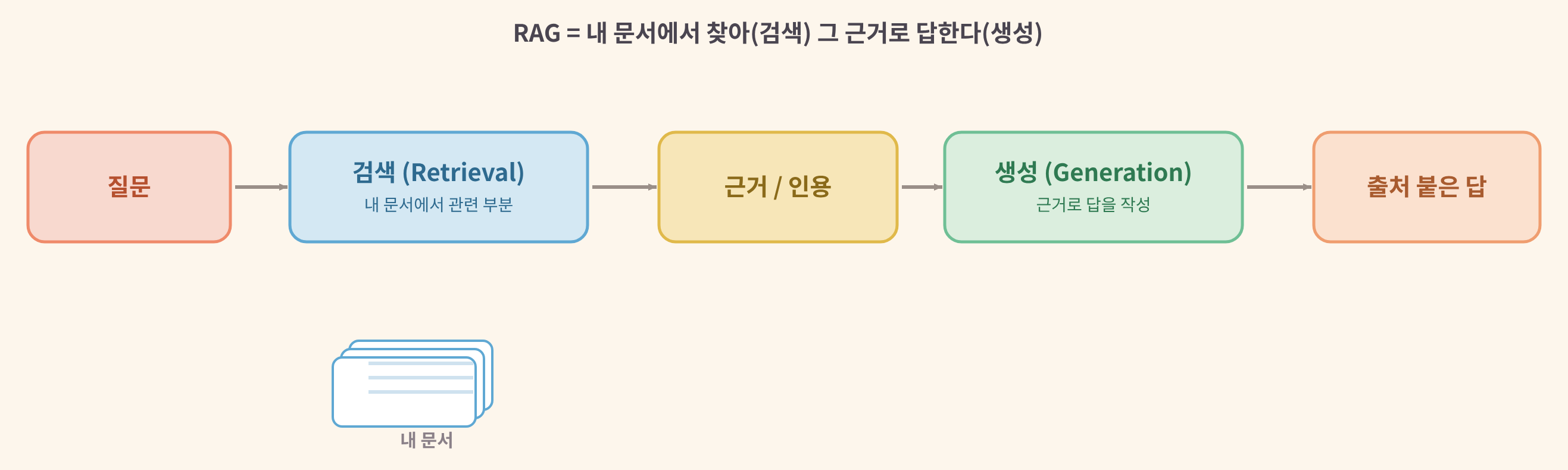
흐름은 단순하다. 질문이 들어오면 먼저 내 문서에서 관련 부분을 찾고(Retrieval), 그 근거를 바탕으로 답을 만든다(Generation). 결과적으로 환각이 줄고, 답에 출처가 붙는다. 일반 지식으로 답하던 AI가 "내가 준 자료에 근거해" 답하는 AI로 바뀌는 셈이다. 그런데 여기엔 함정이 하나 있다. 준 자료가 부실하면 답도 부실해진다. 이걸 직접 확인해 보자.
직접 해 보기 ① 좋은 문서 vs 부실한 문서

아래 두 문서를 내려받자. 같은 회사의 같은 주제(휴가 규정)인데, 하나는 표와 항목으로 잘 정리된 충실한 문서이고 다른 하나는 몇 줄짜리 부실한 메모다.
- 충실한 문서 — 햇살소프트 휴가 규정.pdf (종류별 일수, 신청 절차, 승인 권한, FAQ까지)
- 부실한 메모 — 휴가 관련 메모.pdf ("연차 쓰고 팀장한테 말하세요" 수준)
이제 ChatGPT나 Claude, Gemini 중 아무거나 열어 두 문서를 따로따로 올리고, 똑같은 질문을 던진다.
- "본인이 결혼하면 경조사 휴가를 며칠 받나요?"
- "병가를 쓸 때 진단서가 꼭 필요한가요?"
- "남은 연차는 언제 소멸하나요?"
결과는 확연히 갈린다. 충실한 문서를 올리면 "본인 결혼은 5일입니다", "3일 이상 연속 사용할 때 진단서가 필요합니다", "다음 해 3월 31일에 소멸합니다"처럼 근거가 또렷한 답이 나온다. 어디서 가져왔는지 문서의 해당 부분도 짚어 준다. 반면 부실한 메모를 올리면 "문서에 구체적인 일수가 없습니다", "회사 규정을 따른다고만 적혀 있습니다"라며 답을 못 하거나 두루뭉술해진다.
여기서 오늘의 핵심이 나온다. RAG의 품질은 모델이 아니라 내가 넣는 문서의 품질이 절반을 정한다. 같은 AI, 같은 질문인데 자료가 바뀌니 답이 통째로 달라졌다. 그래서 "좋은 답을 받으려면 좋은 문서를 넣는다"가 RAG의 첫 번째 규칙이다.
어디서 어떻게 — ChatGPT / Claude / Gemini 비교
방금 한 일(문서를 올려 그 근거로 답하게 하기)을 세 서비스가 각각 다른 이름과 방식으로 제공한다. 한 번 쓰고 마는 첨부냐, 계속 두고 쓰는 공간이냐로 나눠 보면 정리가 쉽다.
| 서비스 | 대화 중 한 번 첨부 | 계속 두고 쓰는 공간 | 처리 방식의 특징 |
|---|---|---|---|
| ChatGPT | 첨부(클립 아이콘) | 프로젝트(Projects), 맞춤 GPT의 지식(Knowledge) | 올린 문서를 검색해 관련 조각만 꺼내 씀 |
| Claude | 첨부 / 드래그 | 프로젝트(Projects)의 지식 | 문서를 긴 컨텍스트에 통째로 올려 직접 참조, 인용이 잘 붙음 |
| Gemini | 파일 업로드 | Gem + Google Drive 연동 | Drive 문서를 실시간 동기화. 인용 중심 작업은 NotebookLM이 특화 |
공통점. 셋 다 (1) 대화에 파일을 그냥 끌어다 놓고 바로 물어볼 수 있고, (2) 프로젝트나 Gem 같은 공간에 자료를 저장해 매번 올리지 않고 재사용할 수 있다.
차이점. 속을 보면 방식이 다르다. ChatGPT는 문서가 많아지면 관련 부분만 검색해 꺼내 쓰고, Claude는 문서를 통째로 긴 맥락에 올려 더 직접적으로 참조하며 인용을 잘 단다. Gemini는 Google Drive와 실시간으로 연결되는 게 강점이고, 근거를 클릭해 원문으로 점프하는 인용 경험은 Google의 NotebookLM이 가장 앞선다. 무엇이 정답인지는 일에 달렸다. 큰 문서 더미를 오래 다루면 Claude나 Gemini가, 자료가 자주 바뀌면 Drive 연동의 Gemini가 편하다.
직접 해 보기 ② 인용을 클릭해 원문으로
같은 충실한 문서를 NotebookLM에 올리고 질문하면, 답에 인라인 인용이 붙는다. 그 인용을 클릭하면 근거가 된 원문 위치가 정확히 하이라이트된다. "5일"이라는 답의 출처가 문서의 어느 줄인지 바로 확인되는 셈이다. 이렇게 근거를 눌러 원문으로 점프하는 경험이 RAG의 신뢰성을 가장 잘 보여 준다. NotebookLM은 사용자가 준 소스에만 근거해 답하고 모든 응답에 인용을 붙여 환각을 크게 줄인다 (NotebookLM 소개).
정리 — 사실을 강요할 순 없어도 근거는 쥐여 줄 수 있다
오늘의 한 문장. RAG는 답하기 전에 내 문서를 찾아보게 해서 환각을 줄이고 출처를 붙인다. 단, 준 자료 안에서만. 좋은 문서를 넣으면 또렷한 답이, 부실한 문서를 넣으면 부실한 답이 나온다. 도구가 ChatGPT든 Claude든 Gemini든 이 원리는 똑같다.
다음 글에서는 이 RAG와 프롬프트를 하나로 묶어, 코드 없이 나만의 AI 도우미를 만들어 본다.