
앞에서 컴퓨터가 사진을 알아보는 법을 봤다. 이번엔 정반대다. 알아보는 게 아니라 새로 그려 내는 AI, 생성 AI다. 글 몇 줄을 넣으면 한 번도 존재한 적 없는 그림이 튀어나오는 그 신기한 일이, 사실은 어떻게 작동하고 어떻게 여기까지 왔는지 본다.
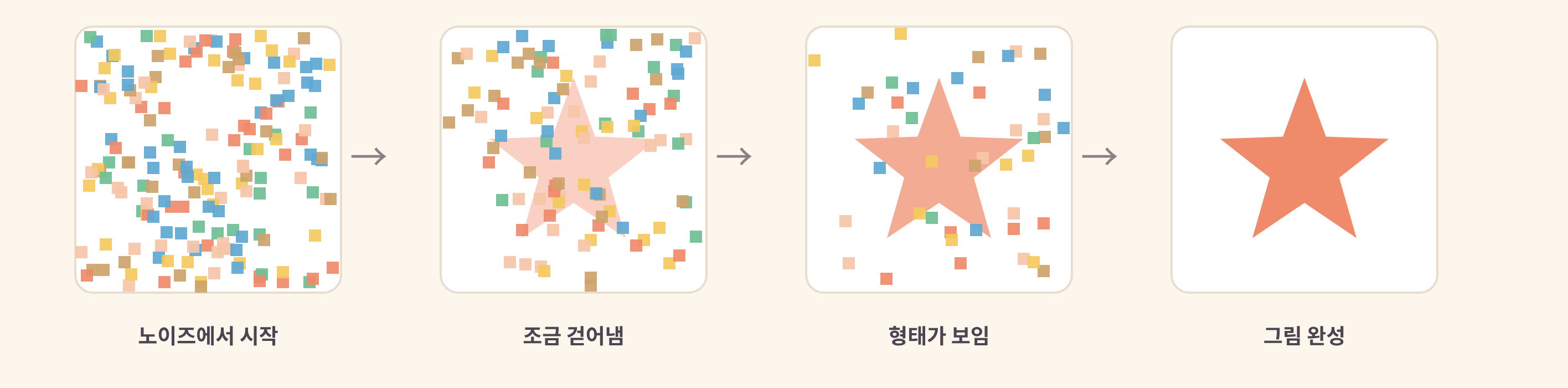
시작은 의외로 지지직거리는 노이즈 화면이다. 생성 AI는 잡음 덩어리에서 출발해 "이건 고양이여야 해"라는 방향으로 조금씩 잡음을 걷어내며 형태를 잡아 간다. 이게 Diffusion(확산)의 직관이다.
생성은 복사가 아니다 — 배운 것에서 새로 뽑기
흔한 오해부터 풀자. 생성 AI는 어디선가 그림을 베껴 오는 게 아니다. 모델은 수많은 이미지를 보면서 "고양이다움", "별이 빛나는 밤다움" 같은 분포(어떤 느낌이 고양이스러운지의 큰 경향)를 익힌다. 그림을 만들 때는 그 분포에서 새 표본 하나를 뽑는다. 그래서 같은 프롬프트를 넣어도 매번 결과가 다르고, 모델이 바뀌면 화풍도 달라진다.
위 그림처럼, 출발은 순수한 잡음이다. 모델은 "이 잡음에서 고양이를 향해 조금 덜 지저분하게" 만드는 일을 수십 번 반복한다. 한 단계씩 잡음이 걷히며 형태가 또렷해지고, 마지막엔 한 장의 그림이 남는다. 베끼기가 아니라, 안개 속에서 형태를 끄집어내는 일에 가깝다.
잡음에서 4K까지 — 이미지 생성 AI가 걸어온 길
지금의 매끈한 결과는 갑자기 나온 게 아니다. 10여 년의 흐름을 압축하면 이렇다.
- 2014, 씨앗 — GAN(Generative Adversarial Network: 생성적 적대 신경망)이 등장한다. 위조지폐범과 감별사가 서로 속고 잡아내며 실력을 키우듯, 두 신경망이 경쟁하며 그럴듯한 이미지를 만든다. 신선했지만 학습이 불안정해 다루기 까다로웠다.
- 2022, 폭발 — Diffusion 방식이 판을 바꾼다. 그해 Stable Diffusion이 모델 가중치를 통째로 공개하면서, 누구나 자기 PC에서 그림을 만들고 입맛대로 미세조정하는 생태계가 터졌다. 같은 시기 DALL-E 2와 Midjourney가 "글로 그림"을 대중에게 각인시켰다.
- 2023~2024, 정교화 — SDXL, SD 3.5처럼 해상도와 프롬프트 충실도가 올라가고, ControlNet/LoRA 같은 도구로 구도와 화풍을 정밀하게 제어하게 됐다.
- 2025~현재, 통합 — 이미지 전용 모델을 넘어, 언어 모델이 이미지까지 함께 다루는 흐름으로 옮겨 갔다. Google의 Nano Banana(Gemini 2.5 Flash Image, 2025년 8월)가 인물 일관성과 자연스러운 편집으로 화제가 됐고, 후속인 Nano Banana Pro(Gemini 3 Pro Image, 2025년 11월)는 4K 해상도와 이미지 속 글자(다국어) 표현, 검색으로 사실을 확인해 그리는 능력까지 더했다 (Google 발표).
모델별 특징을 한 표로 정리하면 흐름이 더 또렷하다.
| 모델 | 종류 | 등장 | 한 줄 특징 |
|---|---|---|---|
| GAN | 역사 | 2014 | 생성 AI의 씨앗. 두 신경망의 경쟁 학습, 다루기 까다로움 |
| Stable Diffusion 1.5 | 오픈 | 2022 | 가중치를 공개한 최초의 대중 모델, 로컬 생태계가 폭발 |
| SDXL | 오픈 | 2023 | 해상도/구도 향상, 정교한 제어(ControlNet/LoRA) |
| Stable Diffusion 3.5 | 오픈 | 2024 | 프롬프트 충실도와 글자 표현 개선 |
| Z-Image | 오픈 | 2025 | 가볍고 빠른 고품질 생성, 한 장을 짧은 시간에 |
| Nano Banana | 폐쇄 | 2025.8 | 인물/사물 일관성과 자연스러운 편집이 강점 |
| Nano Banana Pro | 폐쇄 | 2025.11 | 4K, 이미지 속 글자 렌더링과 검색 기반 사실성에서 현재 최고 수준 |
두 갈래 — 오픈(Stable Diffusion)과 폐쇄(Nano Banana)
지금 이미지 생성은 크게 두 갈래로 갈린다. 가중치를 공개한 오픈 모델(Stable Diffusion 계열)과, 앱/API로만 쓰는 폐쇄 모델(Nano Banana 계열)이다. 우열의 문제가 아니라 쓰임이 다르다.
| 축 | Stable Diffusion 계열 (오픈) | Nano Banana 계열 (폐쇄) |
|---|---|---|
| 실행 | 내 PC/서버에서 직접 | 클라우드(앱/API) |
| 가중치 | 공개 — 미세조정/제어 자유 | 비공개 |
| 비용 | 하드웨어만 있으면 사실상 무제한 | 무료 플랜은 한도, 이후 유료 |
| 강점 | 커스터마이즈, 데이터 비공개, 대량 생성 | 손쉬움, 글자 렌더링, 일관성, 사실성 |
| 약점 | 품질이 튜닝/하드웨어에 좌우됨 | 폐쇄형, 한도/정책에 의존 |
둘 중 하나를 고르는 게 아니라, 일에 맞게 갈아 끼우는 감각이 중요하다. 빠른 초안이나 글자가 또렷한 포스터 한 장은 폐쇄형이 편하고, 회사 자료를 외부에 올릴 수 없거나 같은 화풍으로 수백 장을 찍어야 한다면 오픈 모델을 내 서버에서 돌리는 쪽이 낫다.
온프렘으로도 — 오픈 모델을 내 서버에서
온라인 서비스로 감을 잡았다면, 같은 작업을 오픈 모델로 직접 띄워 비교할 수 있다. 대표 오픈 모델은 SDXL, Stable Diffusion 3.5, 가볍고 빠른 Z-Image이고, 풀기능 작업 도구로는 Forge WebUI가 많이 쓰인다. 수업에서는 이 오픈 모델들을 온프렘(사내 서버)에 올려 같은 프롬프트로 동시에 생성해 비교하고, 미세조정까지 직접 시연한다.
정리하면 이런 짝이 된다. 온라인으로 손쉽게 체험하는 Gemini(Nano Banana)나 ImageFX, Adobe Firefly가 한쪽이라면, 그와 같은 일을 가중치 공개 모델로 내 서버에서 재현하는 게 다른 쪽이다. 온라인으로 "무엇이 되는지"를 보고, 온프렘으로 "내 데이터로 어떻게 쓰는지"를 잇는다.
Prompt는 그림의 설계도

모델이 무엇이든, 잡음을 어느 방향으로 걷어낼지 정해 주는 건 결국 프롬프트다. 그래서 프롬프트가 구체적일수록 의도에 가까워진다. 네 가지를 조합하면 감을 잡기 쉽다. 주제 + 스타일 + 조명 + 구도.
예를 들어 "고양이"라고만 하면 막연한 고양이가 나오지만, "창가에 앉아 햇빛을 받는 주황 고양이, 따뜻한 역광, 수채화 스타일, 클로즈업"이라고 하면 머릿속 그림에 훨씬 가까워진다. 막연한 한 줄이 흐릿한 결과를 부르는 건 그림에서도 똑같다.
직접 해 보기 — 같은 주제, 다른 그림
같은 주제를 스타일만 바꿔 여러 장 만들어 보면 "같은 글, 다른 그림"이 한눈에 들어온다 (Gemini의 이미지 생성으로 해 볼 수 있다). 예를 들어 "비 오는 밤의 도시 골목, 네온 반사"를 주제로 두고 사진풍, 수채화, 픽셀아트 세 가지로 뽑아 본다.
그다음 네 요소(주제/스타일/조명/구도)를 하나씩 넣고 빼며 결과가 어떻게 변하는지 비교한다. 조명을 "역광"에서 "한낮의 강한 햇빛"으로 바꾸기만 해도 분위기가 통째로 달라진다. 글자가 들어간 포스터를 만들어 보면 모델 차이가 특히 도드라진다.
생성에서 끝이 아니다. 이미 만든 이미지의 일부를 지우고 새로 채우거나(인페인팅), 테두리 바깥으로 화면을 넓히는(아웃페인팅) 편집도 같은 원리로 된다 (Adobe Firefly의 생성 채우기). 잡음을 걷어내는 일을 "이 부분만"으로 좁히면 부분 수정이 되는 셈이다.
정리 — 맥락이 결과를 좌우한다
생성 AI는 베끼는 게 아니라 학습된 분포에서 새로 그리고, 그 방향을 정하는 건 프롬프트(맥락)다. 10년 사이 GAN에서 Diffusion으로, 다시 오픈과 폐쇄 두 갈래로 갈라지며 발전했지만, "맥락이 결과를 좌우한다"는 핵심은 그대로다. 이 감각은 내일 다룰 LLM의 컨텍스트로 이어진다.
다음 글에서는 눈이 아니라 귀로 간다. 소리를 알아듣고(음성 인식), 목소리를 만들고(음성 합성), 곡까지 지어내는 AI를 직접 만져 본다.