
지금까지는 눈으로 보는 AI였다. 이번엔 귀다. 그런데 컴퓨터에게는 소리도 결국 숫자다. 마이크에 말하면 화면의 파형이 출렁이는데, 그 출렁임이 바로 숫자의 연속이다. AI는 이 숫자를 글자로 옮기거나(음성 인식), 반대로 글자를 소리로 만든다(음성 합성). 입력을 넣으면 출력이 나오는 함수라는 점은 그림이든 소리든 똑같다.
소리로 하는 네 가지 일
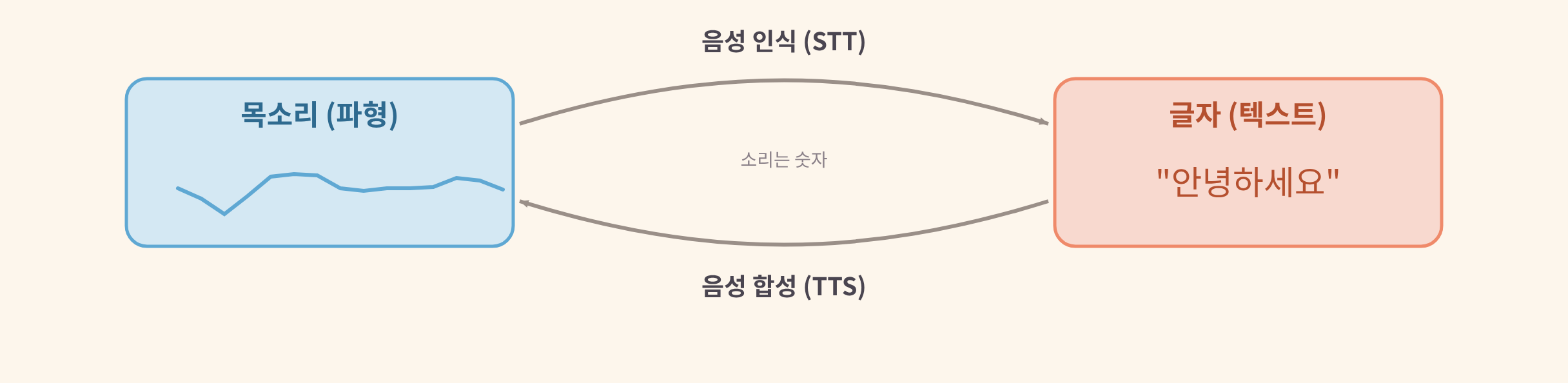
- 음성 인식(STT(Speech-to-Text: 음성 인식)) — 목소리(파형)를 글자로. 회의록과 자막의 바탕이다.
- 음성 합성(TTS(Text-to-Speech: 음성 합성)) — 글자를 목소리(파형)로. 내비게이션과 오디오북, 접근성에 쓰인다.
- 음성 복제 — 짧은 샘플로 특정 목소리의 특징을 익혀 그 목소리로 말하게 한다. 강력하지만 악용 위험(딥페이크)이 큰 기술이다.
- 음악 생성 — 가사와 분위기를 주면 보컬과 반주가 붙은 완성곡을 만든다.
위 그림처럼 음성 인식과 합성은 같은 다리를 양방향으로 건너는 일이다. 한쪽은 파형에서 글자로, 다른 쪽은 글자에서 파형으로. 가운데에 "소리는 숫자"라는 사실이 놓여 있다.
직접 해 보기 ① 음성 인식 — 내 말이 글이 된다
짧은 문장을 또박또박, 빠르게, 사투리로 각각 말해 보고 받아쓰기 결과를 비교한다 (AssemblyAI 같은 음성 인식 데모). 발음이 또렷할 때, 소음이 섞일 때, 전문용어가 나올 때 정확도가 어떻게 달라지는지 보인다. 한국어와 영어를 섞은 문장을 넣어 보면 더 재미있다.
이 온라인 데모가 쓰는 것과 같은 일을, 오픈소스 모델로 내 서버에서도 돌릴 수 있다. 음성 인식의 판을 바꾼 건 OpenAI가 공개한 Whisper인데, 이를 빠르게 만든 faster-whisper가 자막/전사에 널리 쓰인다. 폰이나 소형 기기에서 실시간으로 돌리는 초경량 Moonshine, 한국어 등 특정 언어로 미세조정하기 좋은 wav2vec2, 산업용 파이프라인의 NVIDIA NeMo까지 선택지가 넓다.
직접 해 보기 ② 음성 합성과 복제

같은 문장을 여러 목소리와 감정으로 합성해 비교해 본다 (ElevenLabs). 그다음 본인 목소리를 10초에서 30초쯤 녹음해 복제하고, 그 목소리로 아무 문장이나 읽게 해 보면, 합성 음성이 사람과 구분하기 어려운 수준이라는 걸 바로 느낀다.
바로 여기서 멈춰 생각할 게 있다. 이렇게 쉬운 복제가 남의 목소리에 쓰이면 그게 보이스피싱이고 딥페이크다. 음성 복제는 반드시 본인 목소리로만 해 보자. 타인의 목소리를 동의 없이 복제하는 건 하지 않는다. 기술이 강력할수록 이 선이 중요해진다.
합성 TTS도 오픈 모델이 빠르게 따라왔다. 다국어를 가볍고 빠르게 합성하는 MeloTTS, 몇 초 샘플로 목소리를 복제하는 표현형 CosyVoice, 기기 안에서 초고속으로 도는 Supertonic이 대표적이다. 온라인 서비스로 품질을 체감했다면, 같은 합성과 복제를 이 오픈 모델로 온프렘에서 직접 돌려 비교할 수 있다.
직접 해 보기 ③ 음악 — 가사 한 줄이 곡이 된다
주제와 장르, 분위기를 적어 주면 완성곡이 나온다 (Suno). 예를 들어 "비 오는 날의 잔잔한 로파이, 한국어 가사"로 한 곡 만들고, 가사나 장르를 바꿔 다시 만들며 차이를 들어 본다. 악기를 못 다뤄도 누구나 곡을 얻는 시대다. 단, 저작권과 상업적 사용 조건은 서비스마다 다르니 그 부분은 따로 확인해야 한다.
노래 생성도 이제 오픈 모델로 가능하다. 보컬과 반주가 붙은 곡을 만드는 ACE-Step과 DiffRhythm, 멜로디/조건을 주는 Meta의 MusicGen, 트랙과 효과음 중심의 Stable Audio가 대표적이다.
같은 일의 두 길 — 온라인 SOTA와 온프렘 OSS
지금까지 만진 온라인 서비스에는, 같은 일을 하는 오픈소스 모델이 거의 다 짝으로 존재한다. 손쉬운 온라인 SOTA(State of the Art: 최고 성능)로 "무엇이 되는지"를 체험하고, 가중치를 공개한 OSS 모델을 내 서버에 띄워 "내 데이터로 어떻게 쓰는지"를 잇는 식이다. 분야별로 정리하면 이렇다.
음성 인식(STT)
| 온라인 SOTA (무료 플랜으로 체험) | 대응 온프렘 OSS 모델 |
|---|---|
| AssemblyAI, Deepgram, Otter.ai | faster-whisper, Moonshine, wav2vec2, NeMo |
음성 합성(TTS)
| 온라인 SOTA (무료 플랜으로 체험) | 대응 온프렘 OSS 모델 |
|---|---|
| ElevenLabs, Azure Speech, Google Cloud TTS | MeloTTS, CosyVoice, Supertonic |
음악 생성
| 온라인 SOTA (무료 플랜으로 체험) | 대응 온프렘 OSS 모델 |
|---|---|
| Suno, Udio, Stable Audio | ACE-Step, DiffRhythm, MusicGen |
수업에서는 이 오픈 모델들을 온프렘 서버에 올려, 여러 모델을 같은 입력으로 동시에 돌려 비교하는 화면을 직접 보여 준다. 온라인에서 들은 그 품질이, 내 서버의 오픈 모델에서는 어떻게 나오는지 나란히 듣는 셈이다.
오픈 모델은 어떻게 여기까지 왔나, 그리고 무엇을 고를까
세 분야 모두 오픈 모델의 발전 궤적이 비슷하다. 음성 인식은 라벨 없는 음성으로 표현을 학습한 wav2vec2(2020)가 길을 열고, 다국어 전사를 대중화한 Whisper(2022)가 판을 바꾼 뒤, 속도(faster-whisper)와 엣지 실시간(Moonshine)으로 갈라졌다. 음성 합성은 기계음에서 출발해 자연스러운 end-to-end 합성으로, 다시 몇 초 샘플로 목소리를 복제하고 기기 안에서 초고속으로 도는 단계까지 왔다. 음악은 조건부 작곡을 보여 준 MusicGen(2023)에서, 보컬과 반주가 붙은 노래를 오픈으로 만드는 ACE-Step/DiffRhythm(2025)으로 넘어왔다.
그래서 무엇을 고를까. 품질과 편의는 여전히 폐쇄형 온라인이 앞서지만, 실시간/온디바이스/목소리 복제/미세조정/비용 통제에서는 오픈 모델이 더 유리한 영역이 뚜렷하다. 빠른 PoC(Proof of Concept: 개념 증명)나 범용 품질이 필요하면 온라인 무료 플랜으로 시작하고, 민감한 데이터를 밖으로 못 내보내거나 같은 작업을 대량으로 처리하고 내 도메인에 맞게 다듬어야 하면 온프렘 OSS로 간다. 정답은 하나가 아니라, 같은 작업을 두 길에 나란히 올려 비교해 보는 안목이다.
정리 — 소리도 입력에서 출력으로, 그리고 두 갈래
음성 인식, 음성 합성, 음악 생성 모두 "입력을 넣으면 출력이 나오는" 같은 함수다. 소리를 숫자로 보는 순간, 글자와 소리 사이를 자유롭게 오가는 일이 가능해진다. 그리고 그 일은 손쉬운 온라인 서비스와, 가중치를 공개한 온프렘 OSS라는 두 길로 똑같이 닿을 수 있다. 힘이 커질수록 "본인 것만 복제한다" 같은 윤리의 선이 함께 따라와야 한다는 점도 잊지 말자.
여기까지가 보고 듣고 만드는 AI였다. 다음 글에서는 이미지/소리/글을 한꺼번에 다루는 멀티모달로 넘어가, 오늘 본 것들을 하나로 묶어 본다.