
지금까지 따로따로 만져 봤다. 이미지, 소리, 글, 음악. 이번엔 이것들을 한 줄로 잇는다. 핵심은 단순하다. 한 도구의 출력이 다음 도구의 입력이 된다. 이미지에서 대본이 나오고, 대본에서 목소리가 나오고, 거기에 음악을 입히면 작은 영상 한 편이 된다.
이렇게 텍스트/이미지/음성/음악처럼 서로 다른 형태(모달리티)를 다루고 이어 붙이는 것을 멀티모달이라고 한다. AI 기능을 레고 블록처럼 조립하는 감각인데, 이게 내일 배울 서비스 설계의 바탕이 된다.
출력을 입력으로 — 네 칸짜리 창작 파이프라인

오늘 만든 도구들을 한 흐름으로 엮어 "30초짜리 장면 + 내레이션 + 배경음악" 한 세트를 만들어 본다. 각 단계의 결과물이 다음 단계의 재료가 되는 게 보이도록 의식하며 따라가 보자.
- 이미지 — 장면 한두 컷을 만든다 (Gemini). 예: "노을 지는 항구의 작은 등대".
- 대본 — 그 장면 이미지를 올리고 어울리는 내레이션을 받는다 (Claude). "이 장면에 어울리는 20초 내레이션을 따뜻한 톤으로 써 줘."
- 내레이션 — 대본을 목소리로 합성한다 (ElevenLabs). 목소리와 감정을 골라서.
- 배경음악 — 장면 분위기에 맞는 짧은 곡을 만든다 (Suno).
마지막으로 이미지/내레이션/음악을 슬라이드나 간단한 편집기에 얹으면 30초 결과물이 묶인다. 시간이 부족하면 음악과 자막은 건너뛰고 이미지와 내레이션까지만 완성해도 좋다. 중요한 건 완성도가 아니라 출력이 입력으로 이어지는 연결의 감각이다.
왜 이게 중요한가
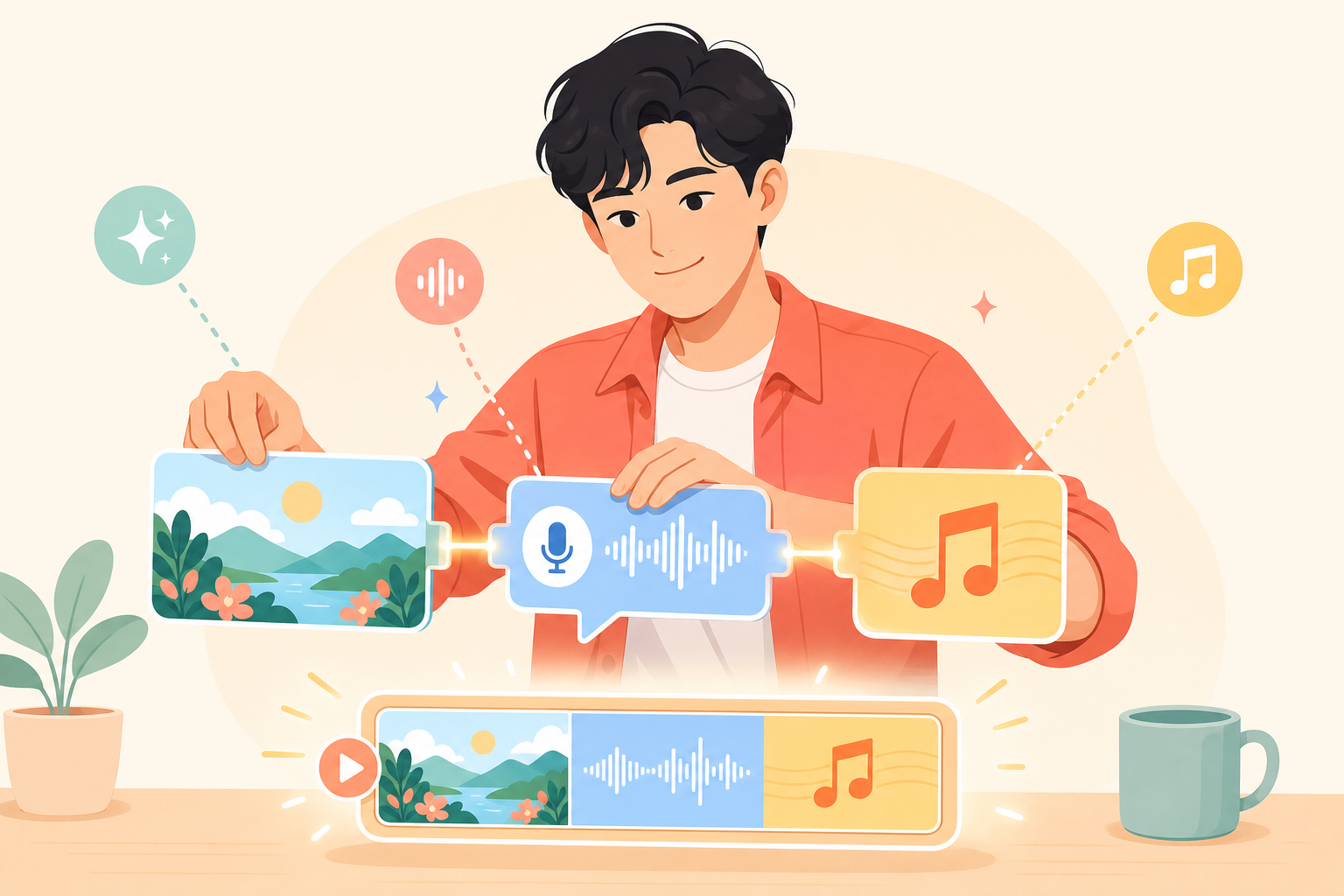
한 도구가 모든 걸 다 하지 않는다. 대신 각 도구의 출력을 다음 도구의 입력으로 넘기면, 혼자서는 못 할 일이 흐름으로 완성된다. 이미지 생성기는 대본을 못 쓰고, 음성 합성기는 그림을 못 그리지만, 둘을 이으면 내레이션이 깔린 장면이 된다. 이 "조립" 감각 하나가 앞으로 만들 거의 모든 AI 서비스의 뼈대다.
팀이 있다면 결과물을 서로 보여 주며 "어떤 도구의 출력을 어디에 연결했는지" 한 줄로 설명해 보자. 같은 30초라도 연결 방식이 제각각이라는 걸 알게 된다.
정리 — AI는 레고처럼 조립된다
멀티모달은 거창한 기술이 아니라 "출력을 입력으로 잇는" 단순한 발상이다. 오늘 따로 배운 이미지/소리/글/음악이 사실은 한 파이프라인의 부품이었던 셈이다.
다음 글에서는 하루 동안 만진 AI들을 "입력에서 출력으로" 한 장의 지도로 정리하고, 직접 만들어 본 경험을 바탕으로 딥페이크와 저작권 같은 윤리 문제를 짚어 본다.